이상치 탐지 두번째 시간은 Z-score 방식에 대해서 알아본다.
Z-score는 통계에서 중요한 개념이고, 다른 이름으로 Standard-score라고도 한다. 이 방법은 변수에 가우스 분포가 취하고 있다는 가정으로 시작하고, 관측치가 평균에서 벗어난 표준 편차의 수를 나타낸다. 포인트 그룹의 평균 및 표준 편차와의 관계 측면에서 데이터 포인트를 설명하는 방법이라고 볼 수 있다.
이 score는 데이터 값이 평균보다 큰지 작은지를 확인할 수 있게 해주고, 평균 포인트에서 얼마나 떨어져 있는지를 이해할 수 있도록 도움을 주는데, 보다 구체적으로 Z-score는 데이터 포인트가 평균에서 얼마나 떨어져 있는지를 나타내고 있다.
Z score = (x -mean) / std. deviation
다음과 같이 추정한다.
- 데이터 포인트의 68%는 +/-1 표준 편차 사이에 있다.
- 데이터 포인트의 95%가 +/-2 표준 편차 사이에 있다.
- 데이터 포인트의 99.7%가 +/-3 표준 편차 사이에 있다.
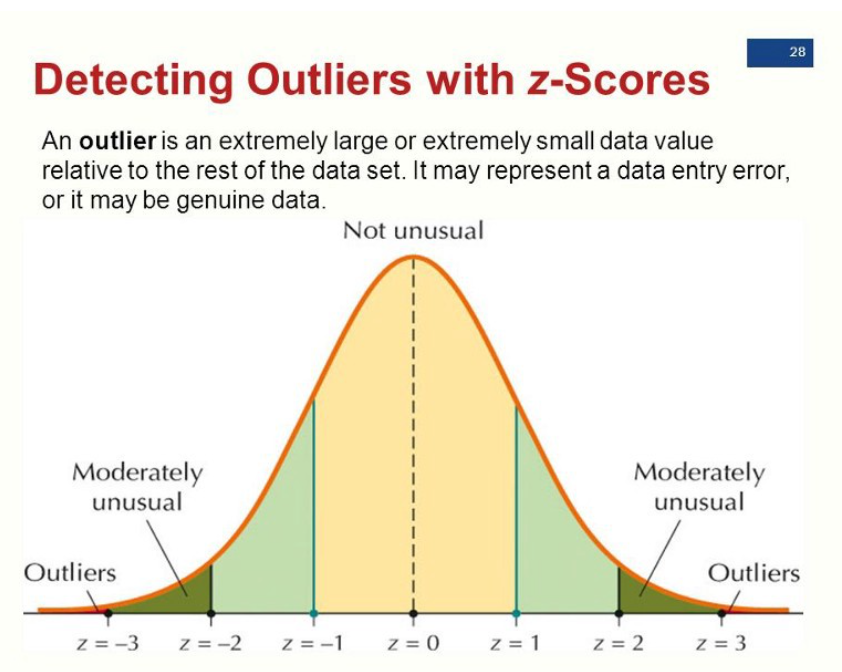
Z-score 및 이상값 정의
여기서 일반적으로 이상값을 z 점수의 계수가 임계값보다 큰 것으로 정의하는데, 이 임계값은 일반적으로 2보다 크고, 3은 공통값으로 본다. 데이터 포인트의 z 점수가 3보다 크면 데이터 포인트가 다른 데이터 포인트와 상당히 다르다는 것을 나타내게 되는데, 이러한 데이터 포인트를 이상값으로 정의한다.
예를 들어 한 설문 조사에서 한 사람의 형재/자매 수를 물었다고 가정하자.
모든 사람으로부터 얻은 데이터가 다음과 같다고 할 때,
| 1, 3, 3, 2, 4, 1, 1, 12, 1, 2, 3, 2, 1, 2, 1 |
전체 데이터 중에서 분명히 12는 이 데이터셋에서 이상값이다.
Z-score에서 점수를 얻는 목적
데이터의 위치와 규모의 영향을 제거하여 서로 다른 데이터셋을 직접 비교할 수 있도록 하는 것이다.
Z-score 방식은 데이터 그룹의 평균 및 표준 편차를 사용하여 중심 경향 및 분산을 측정하는 것이라고 하였다. 평균과 표준 편차는 이상값의 영향을 많이 받기 때문에 문제가 된다. 사실 이상치가 가져 오는 왜곡은 데이터셋에서 이상치를 찾아 제거하는 가장 큰 이유 중 하나라고 보면 된다.
파이썬으로 Z-score 구하기(Z-score in Python)
그럼 파이썬으로 직접 Z-score를 구해보도록 한다.
1 : 라이브러리 로드하기
import numpy as np
2 : 평균(mean)과 표준편차(standard deviation) 계산하기
data = [1, 3, 3, 2, 4, 1, 1, 12, 1, 2, 3, 2, 1, 2, 1]
mean = np.mean(data)
std = np.std(data)
print('데이터의 평균은', mean)
print('데이터의 표준 편차는', std)
>> 데이터의 평균은 2.6
>> 데이터의 표준 편차는 2.6783079235467557
3 : Z-score 계산하기(Z-score가 3보다 크면 이상값으로 출력)
threshold = 3
outlier = []
for i in data:
z = (i-mean)/std
if z > threshold:
outlier.append(i)
print('데이터셋 내의 이상값은', outlier) >> 데이터셋 내의 이상값은 [12]
요렇게 Z-score 방식으로 이상값을 찾는 방법을 정리해보았다 :)
다음번엔 고전적인 방법 중에서 또 다른 방식을 정리해보도록 하겠다.
Clary K